SAP HANA Platform
Die langjährige Strategie der SAP war es, eine von der Datenbank unabhängige Applikationsschicht zur Verfügung zu stellen. Entsprechend lag auch der Fokus der SAP in der Vergangenheit nicht auf der Entwicklung eigener Datenbanken und mit der SAP MaxDB war im SAP Produktportfolio nur eine einzige Datenbank enthalten, die mit den Produkten spezialisierter Datenbankhersteller kaum konkurrieren konnte. Diese Situation hat sich mit der im Jahr 2010 von SAP vorgestellten SAP HANA Plattform drastisch geändert. Mit SAP HANA wurden und werden immer mehr Funktionalitäten, die bislang in der Applikationsschicht angesiedelt waren, in die Datenbank verlagert. Einerseits geht natürlich die Unabhängigkeit der Applikationsschicht von der Datenbankschicht verloren, aber die im folgenden aufgeführten Vorteile machen diesen Nachteil mehr als wett.
Allgemeines
SAP HANA ist eine der ersten Datenbank-Management-Plattformen, die sowohl transaktionale und analytische Datenprozessierung verknüpft und diese anhand eines einzigen Datenbestandes In-Memory durchführt. Dadurch werden Datenredundanzen vermieden und klassische Performanceprobleme, die durch Transport von Daten aus der Datenbank in den Anwendungsserver entstanden, eliminiert.
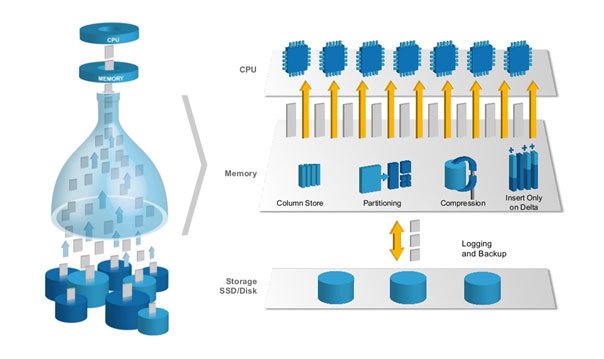
Bringing Transactions and Analytics together
Außerdem ist die In-Memory Technologie für schnelle Datenprozessierung konsequenter und besser umgesetzt. Die gewonnene Performance-Steigerung ermöglicht einerseits große Datenmengen, so gennannte BIG DATA in Echtzeit zu prozessieren. Andererseits steht eine Reihe moderner Tools zur Analyse der Daten zur Verfügung.
Business Data Platform
Beispielsweise werden die oben genannten „Spatial“ und „Graph“ Funktionalitäten häufig in der Logistik und in der Verkehrsplanung für Routenoptimierung und Standortplanungen verwendet. SAP HANA Platform will Ihnen dazu die Tools geben, diese Fragen intuitiver und automatisierter zu beantworten. Ein Anwendungsfall, der in der Vergangenheit komplexen Applikationsschichten vorbehalten war.
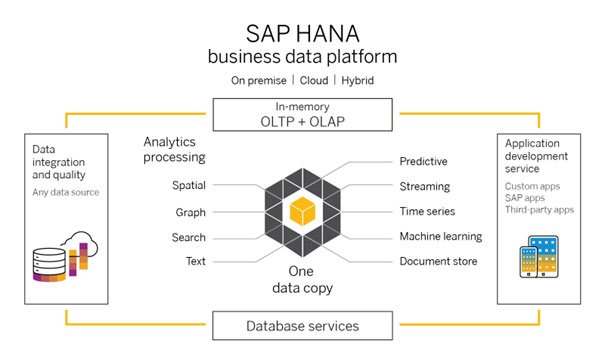
Datenbank Features
SAP HANA erfüllt die Voraussetzungen für Atomizität, Konsistenz, Isolierung und Dauerhaftigkeit (ACID Standards) und den SQL 92 Standard. Es ist eine In-memory spaltenorientierte Datenbank. Diese optimiert die Vorteile des Multicore Processing und Single-Instruction (SIMD). SAP HANA ist standardmäßig spaltenorientiert aber ermöglicht auch den sogenannten row store, der Datenbanktabellen in einer Sequenz aus Zeilen zerlegt und speichert. Damit ist die Tabelle einfacher wiederherstellt und Schreiben von neuen Zeilen ist in dieser Struktur eine relativ einfache Operation.
Column Store
Datenbanktabellen werden in SAP HANA standardmäßig in einer Sequenz von Spalten gespeichert, was für eine in-memory multi-core parallele Prozessierung vorteilhaft ist. Die Daten sind hier in unabhängigen Datenblöcken, die direkt in mehrfachen Kernen des Prozessors simultan verarbeitet werden können, vorpartitioniert. Ein weiterer Vorteil der Spaltenorientierung ist, dass sie keine synthetischen analytischen Indizes benötigt, da die Reihenfolge der Sequenz bereits ein natürlicher Index ist. Sie ermöglicht effiziente Komprimierung, z.B. durch Dictionary Compression. Mit In-memory Column Store kann man on-the-fly Aggregationen durchführen und dadurch Pre-Aggregate und materialisierte Views eliminieren.
Skalierbarkeit
Grundsätzlich ist die Datenmenge in SAP HANA nicht durch Hauptspeicherplatz limitiert, denn die Architektur ermöglicht Daten nicht nur als In-memory Tabellen, sondern auch als Multistore- und Disktabellen zu speichern. Management, Encryption, Backup und Recovery Funktionen sind bei allen Tabellen gleichermaßen gewährleistet. Daten können beim Abrufen aus den In-memory, Multistore- und Disktabellen zusammengefügt werden. Die Speicherlokation einer Tabelle kann jederzeit geändert werden.
Daten aus anderen Datenquellen wie Apache Hadoop und Apache Spark sind ebenfalls über Queries zugänglich ohne diese kostenaufwändig transportieren zu müssen. Funktionen wie SAP SQL Anywhere Suite eingebettet in entfernten Geräten ermöglicht eine Remotedatensynchronisation.
SAP HANA Cloud
Seit 2014 wird SAP HANA neben der klassischen on-premise Installation sowohl in einer Cloud Installation als auch in einer hybriden Umgebung angeboten.
Unterstütze Technologien und Interfaces
Neben ABAP können Entwickler auch in vielen anderen Sprachen programmieren, einschließlich Java, JavaScript, Python, C++, Go, Node.JS, git, github, HTML5. Ferner werden UI Libraries und semistrukturierte Datenformate wie JSON und XML unterstützt. Die Entwicklungsumgebung im SAP HANA Studio ist basiert auf Eclipse. SAP HANA integriert auch TensorFlow und R Server für datenstromorientierte Programmierung, statistische Mustererkennung und Automatisierung von Business Prozessen.
Einordnung in das SAP Universum
Für das SAP Business Warehouse wurde als Übergangslösung zunächst SAP BW 7.5 on HANA angeboten. In der nächsten Generation ist in SAP HANA Platform in SAP BW/4HANA technisch komplett eingebettet und die klassische Funktionen des Business Warehouse und der Datenbank verschmelzen weiter.
Für ERP, insbesondere im Bereich Corporate Finance, sind SAP S/4HANA bzw. Finance in SAP S/4 HANA für SAP HANA optimiert.
Literaturverzeichnis
Kreps, J. (31. July 2014). O'REILLY. Von https://www.oreilly.com/ideas/why-local-state-is-a-fundamental-primitive-in-stream-processing abgerufen
SAP SE. (20. 09 2018). SAP HANA In-Memory Data Platform. Von https://www.sap.com/products/hana.html abgerufen
Sind Sie an weiteren Informationen oder einem fachlichen Austausch interessiert?
Dann kontaktieren Sie uns.
Ihr Ansprechpartner
Alexander Eismann
CALEO Consulting GmbH
Lochhamer Schlag 11
82166 Gräfelfing